前端框架
内网穿透
spring cloud
软件工程
python爬虫
hub
webrtc
iphone
多继承和菱形虚拟继承
cve-2022-21449
AI求解器
传输层
天气数据分析
gns3
使用笔记
Gerber
CSDN 橡皮擦
Release
前向和反向传播
dpi
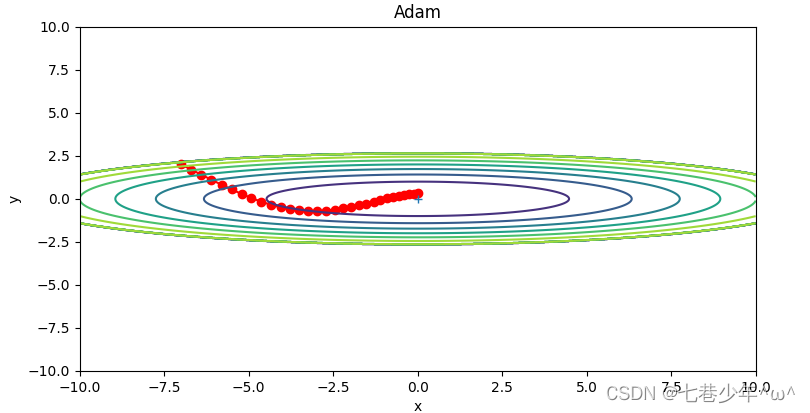
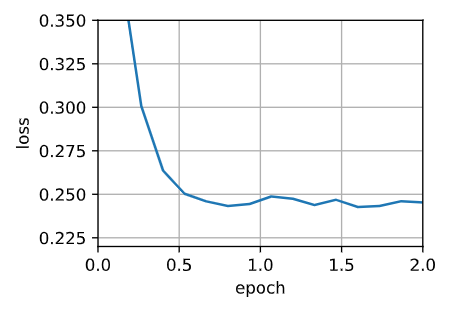
Adam
2024/4/12 3:13:39
深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
深度学习中优化方法—momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam—订正说明(2019.6.25):感谢评论留言的同学指正我的一些笔误,现把他们订正过来,订正的主要内容为:
第二节࿱…
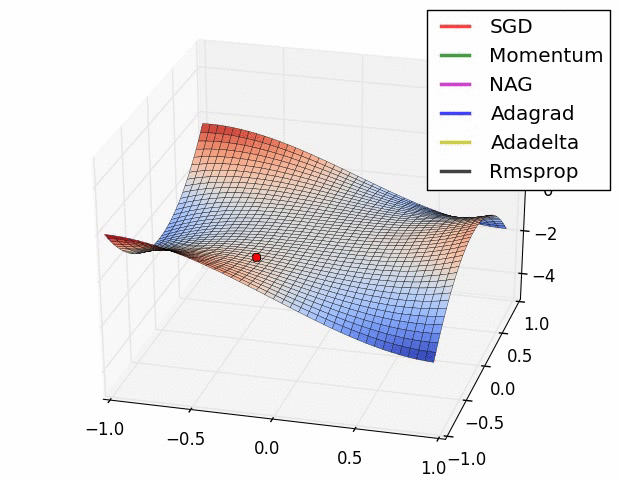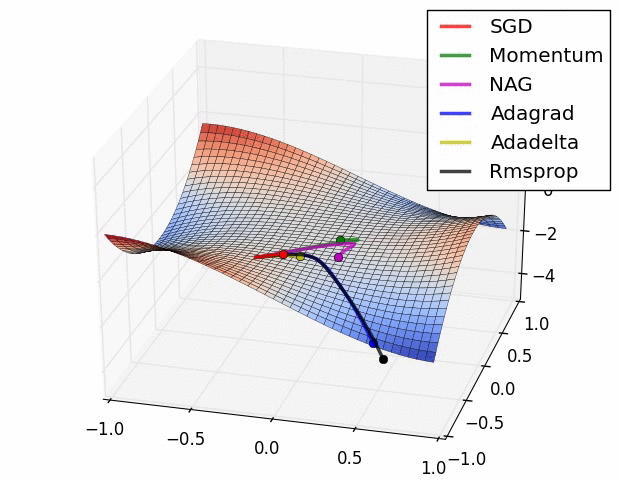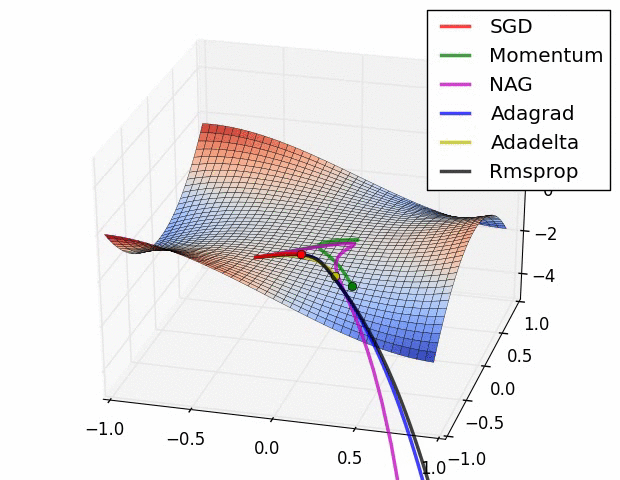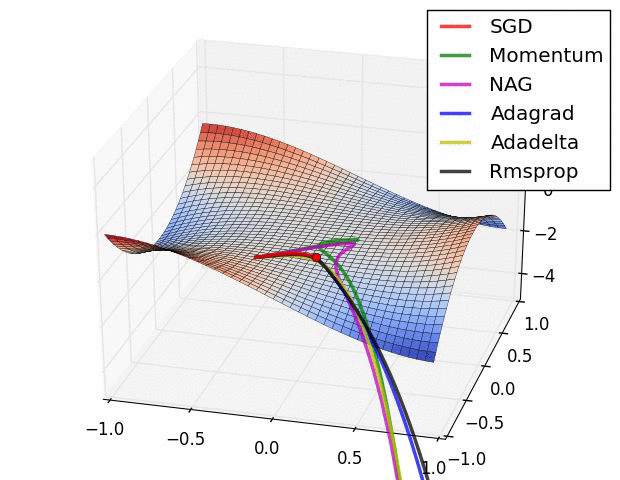
人工智能基础部分21-神经网络中优化器算法的详细介绍,配套详细公式
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分21-神经网络中优化器算法的详细介绍,配套详细公式。本文将介绍几种算法优化器,并展示如何使用PyTorch中的算法优化器,我们将使用MNIST数据集和一个简单的多层感知…

深度学习常用优化算法
最早整理了一些深度学习的基础知识给实验室的师弟师妹看,后来想想还是写个博客大家一起看吧。 批量梯度下降法(Batch Gradient Descent) 在整个数据集上(求出损失函数 J(θ 并)对每个参数 θ 求目标函数 J(θ) 的偏导数…

优化器(Optimizer)介绍
Gradient Descent(Batch Gradient Descent,BGD)
梯度下降法是最原始,也是最基础的算法。
它将所有的数据集都载入,计算它们所有的梯度,然后执行决策。(即沿着梯度相反的方向更新权重ÿ…
第五章.与学习相关技巧—参数更新的最优化方法(SGD,Momentum,AdaGrad,Adam)
第五章.与学习相关技巧 5.1 参数更新的最优化方法 神经网络学习的目的是找到使损失函数的值尽可能小的参数,这是寻找最优参数的问题,解决这个问题的过程称为最优化。很多深度学习框架都实现了各种最优化方法,比如Lasagne深度学习框架…
【深度学习笔记】优化算法——Adam算法
Adam算法
🏷sec_adam
本章我们已经学习了许多有效优化的技术。 在本节讨论之前,我们先详细回顾一下这些技术:
在 :numref:sec_sgd中,我们学习了:随机梯度下降在解决优化问题时比梯度下降更有效。在 :numref:sec_min…

斯坦福CS231n计算机视觉-神经网络参数更新机制
梯度下降法(Gradient descent update,SGD) 最后一行就是梯度下降的公式,只是简单的相乘。
存在问题: 梯度的不连续性会导致参数来回震荡,所以收敛的比较慢。
动量更新(momentum update&#x…